Buffer overflow tutorial (part 1)
A buffer is a temporary area for information storage. At the point when more information gets put by a program or framework process, the additional information floods. It makes a portion of that information leak out into different buffers, which can degenerate or overwrite whatever information they were holding. In a buffer overflow assault, the additional information occasionally contains explicit guidelines for activities proposed by a hacker or malevolent user; for instance, the data could trigger a reaction that harms documents, changes information, or uncovers private data.
Buffer overflow is most likely the best-known type of software security vulnerability. Most programming designers realize what buffer overflow vulnerability is, yet buffer overflow assaults against both inheritance and recently created applications are still ubiquitous. Some portion of the issue is because of the wide assortment of ways buffer overflows can happen, and part is because of the error-prone techniques frequently used to prevent them. Buffer overflows are challenging to find, and notwithstanding, when you detect one, it is generally hard to exploit. Nevertheless, aggressors have figured out how to recognize buffer overflows in a staggering array of products and components.
1 — Understanding the Memory
To completely understand how buffer overflow assaults work, we have to comprehend how the information memory is organized inside a process. At the point when a program runs, it needs memory space to store information. Assuming that the host framework utilizes a virtual memory component, a process virtual address space divides into at least three memory sections.
1. The “Text” section, which is a read-only part of memory, is used to keep up the code of the program at run time.
2. The “Data” section, which is a different location of memory where a process can additionally write information. If the information access this area, the data section will be put on an alternate memory page than the text section.
3. Lastly, the “Stack” section, which is a part of memory imparted to the operating frameworks. It is utilized for storing local variables defined inside functions or information related to system calls.
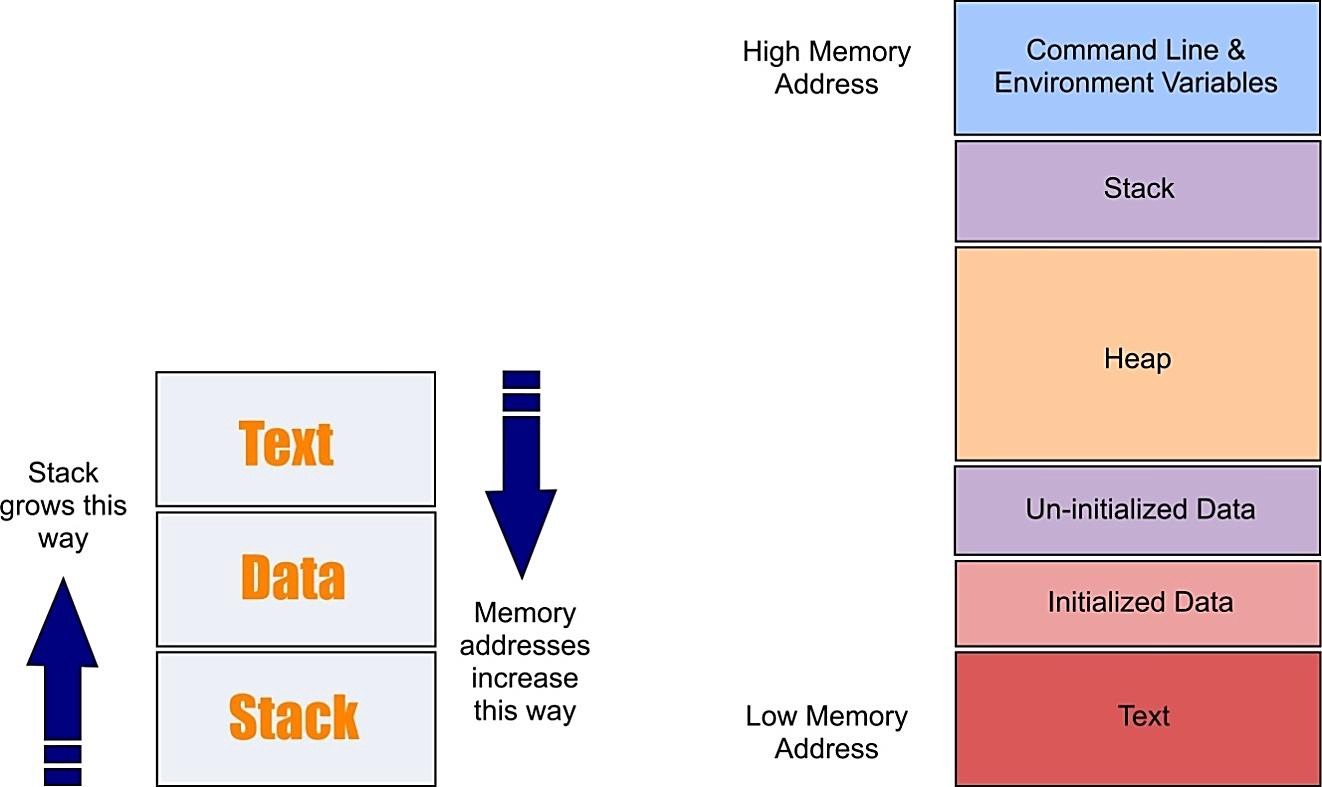
Making apart the initial two memory sections, we will discuss the stack because it is the place a buffer overflow occurs.
As referenced previously, the piece of memory named “Stack” is where a program can store its arguments, its local variable, and some information to control the program execution stream. In the PC architecture, each data stored into the stack adjusted to a multiple of four bytes long. On Intel 32 bit architecture, four bytes long information is called “double word” or “dword.”
The stack on Linux operating framework starts at the high-memory address and develops to the low-memory address. Additionally, the memory on the Intel x86 follows the little-endian convention, so the least significant byte value is stored at the low-memory address, the other bytes follow in increasing order of significance. We can say that the memory is composed of low-memory address to high-memory address.
The “Stack” purported as a result of its stockpiling strategy named Last in First out (L.I.F.O). It implies that the last “dword” put away in memory will be the first retrieved. The activities allowed in the stack are PUSH and POP. PUSH is utilized to embed a “dword” of information into the “Stack,” and POP retrieves the last “dword” by the “Stack.” A caller function uses the “Stack” to pass a parameter for a called function. For each function call, a “Stack” frame is enacted to incorporate the following:
1. The function parameters.
2. The return address — that is useful to store the memory address of the next instruction, called after the function returns.
3. The frame pointer — that is utilized to get a reference to the present “Stack” frame and grant them entrance to local variable and function parameters.
4. And the local variables of a function.
In the x86 Bit architecture, at least three process registries became possibly the most crucial factor with the “Stack”; those are “EIP,” “EBP,” and “ESP.” “EIP” stands for Extended Instruction Pointer, it is a read-only register, and it contains the location of the following instruction to read on the program. It points consistently to the “Program Code” memory portion. “EBP” stands for Extended Base Stack Pointer, and its motivation is to point to the base location of the “Stack.” And “ESP” stands for Extended Stack Pointer; this register intends to tell you where on the “Stack” you are. It implies that the “ESP” consistently marks the highest point of the “Stack.”
“EBP” is significant because it gives a stay point in memory, and we can have many things referenced to that worth. When the function is called inside a program, and we have a few parameters to send to it, the positions in memory are referenced continuously by “EBP” just as the local variables, as shown in the image below.

We know that that the memory composes from low-memory address to high-memory address. Let’s say that we send a string formed by 12 “A” characters. The memory will look like the following figure:

When analyzing this image we see that “PARAM1” point to the location where the information saved in the “Stack,” and as we probably aware “ESP” focuses to the top to the stack so the string is duplicated from “ADDR1” 4 bytes one after another to higher memory, and this happens because it is the best way to stay inside the “Stack.” On the off chance that the function does not control the length of the buffer before composing the information on the “Stack,” and we send a large number of “A” characters, we could end up with a case like in the image below.
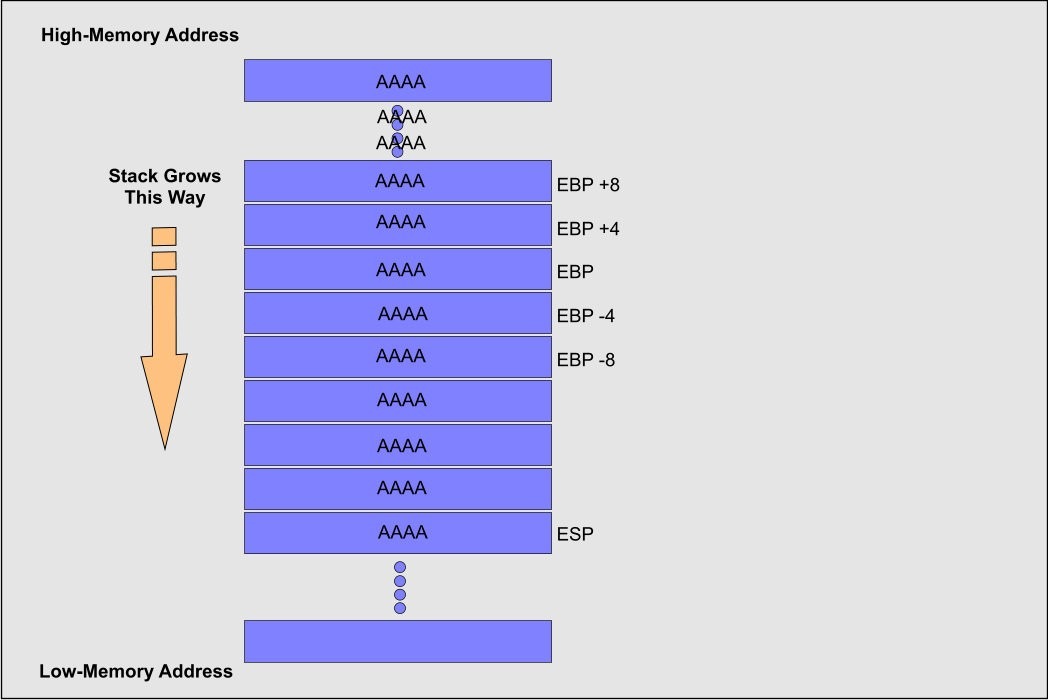
On the off chance that the “EIP” register is overwritten by the “A” characters, at that point, you modified the address to return for the execution of the following instruction. When the “EIP” is overwritten with “noise,” you will have an exemption raised, and the program will stop.
In this following parts, we will show you and explain how to perform a buffer overflow attack and compromise the target computer.