Scan web contents with DIRB
DIRB is a Web Content Scanner. It searches for existing as well as hidden web objects. It fundamentally works by propelling a dictionary-based attack against a web server and analyzing the response. DIRB accompanies a lot of pre-configured attack word lists for simple utilization; however, you can utilize your custom word lists.
Additionally, DIRB now and again can be used as an excellent CGI scanner, yet recollect is a content scanner, not a vulnerability scanner. DIRB fundamental reason for existing is to help in expert web application auditing, especially in security-related testing. It covers some holes that are not covered by traditional web vulnerability scanners.
DIRB searches for specific web objects that other conventional CGI scanners can’t search. It doesn’t seek vulnerabilities, nor does it search for web content that can be vulnerable.
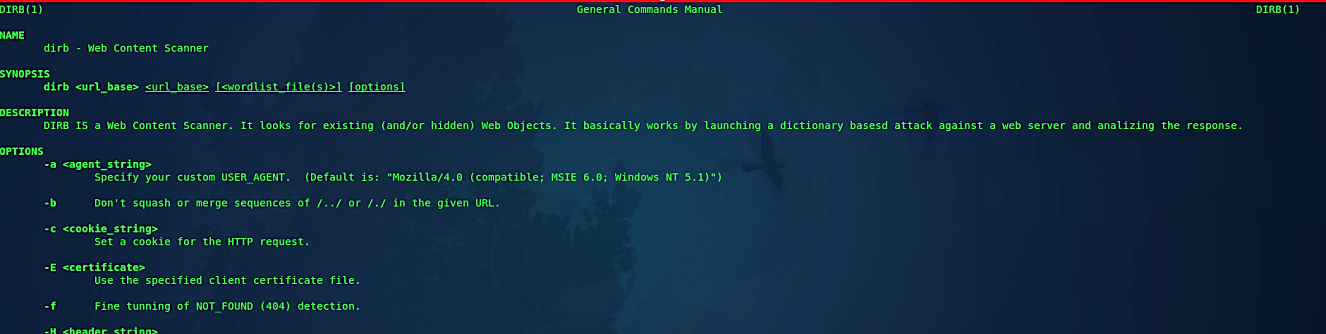
To see all available options for “dirb” use the “man” or the “help” page.
Ex: (root@kali:~# man dirb).
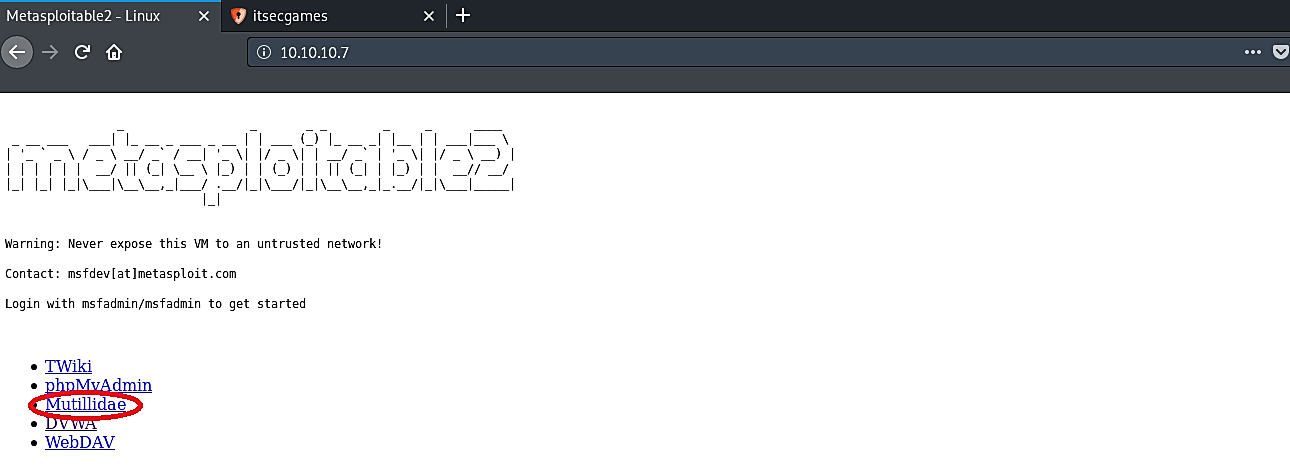
In this specific tutorial, we will be using metasploitable’s “Mutillidae” page to scan for some web content.
Staring this tool is relatively simple; you need to type “dirb” and then specify a web page that you want to audit.
Ex: (root@kali:~# dirb http:10.10.10.7/mutillidae).

As you can see in the screenshot, “dirb” managed to find all available pages in the “Mutillidae” directory. One of the interesting pages is “http://10.10.10.7/mutillidae/robots.txt,” which contains the “robots.txt” file. It is a simple text file placed on your web server, which tells web crawlers like “Googlebot” if they should access a document or not. Improper usage of the robots.txt file can display some useful information to an attacker. Let’s take a look at it.

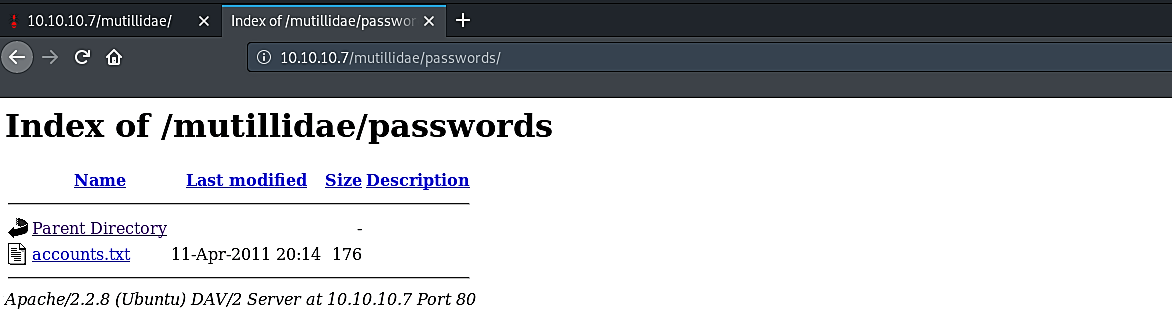
As it is shown in the screenshot, this page was not configured correctly and listed all available directories. One of those directories is related to passwords, which are very intriguing for digging further. To get into that directory, type “http://10.10.10.7/mutillidae/passwords/“ and hit “Enter.”
Excellent, now we have some good information, one of them is related to the web server’s version and port number, and another is a file named “accounts.txt.” From this point, you can search for vulnerabilities related to the web server’s version and perform, and come up with different attacks to escalate your target. In this case, we will click on the “accounts.txt” link to view what is inside.
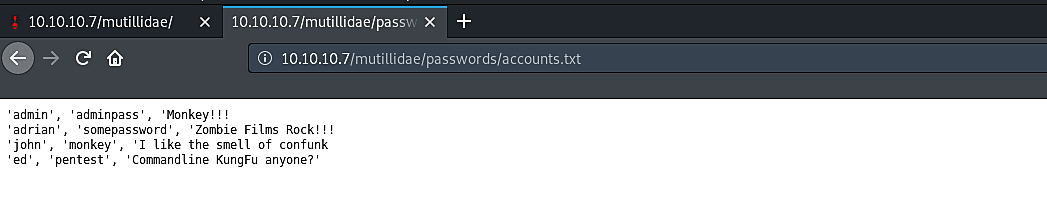
As it’s shown in the screenshot, we managed to find some user credentials which can be used to log in as a legitimate user, and from there, you can continue to experiment with attacks and find more weaknesses of the target.