Security risks with Robots.txt files
The “robots.txt” file is utilized to offer guidelines to web robots, for example, web index crawlers, about areas inside the website that robots are permitted, or not permitted, to crawl and list. The presence of this file doesn’t in itself present any security vulnerability. In any case, it is regularly used to recognize confined or private areas of a website’s contents.
The data in the file may, in this manner, help an aggressor to outline the site’s contents, mainly if a portion of the areas recognized are not linked from somewhere else on the website. If the application depends on “robots.txt” to ensure access to these territories and doesn’t authorize legitimate access command over them, at that point, this may present a severe weakness.
Select the “Robots File” option and start crawling by viewing every directory.

The “Robots File” page has multiple directories (/admin/, /documents/, /images/, /passwords/). We can visit and view every one of them by adding the directory names to the end of the URL.
For instance, to view the “/documents/” directory, type the following URL “http://10.10.10.6/bWAPP/documents/” and hit “Enter.” It will list all available documents and display them on the page.

To view all images, use the “10.10.10.6/bWAPP/images/” URL.

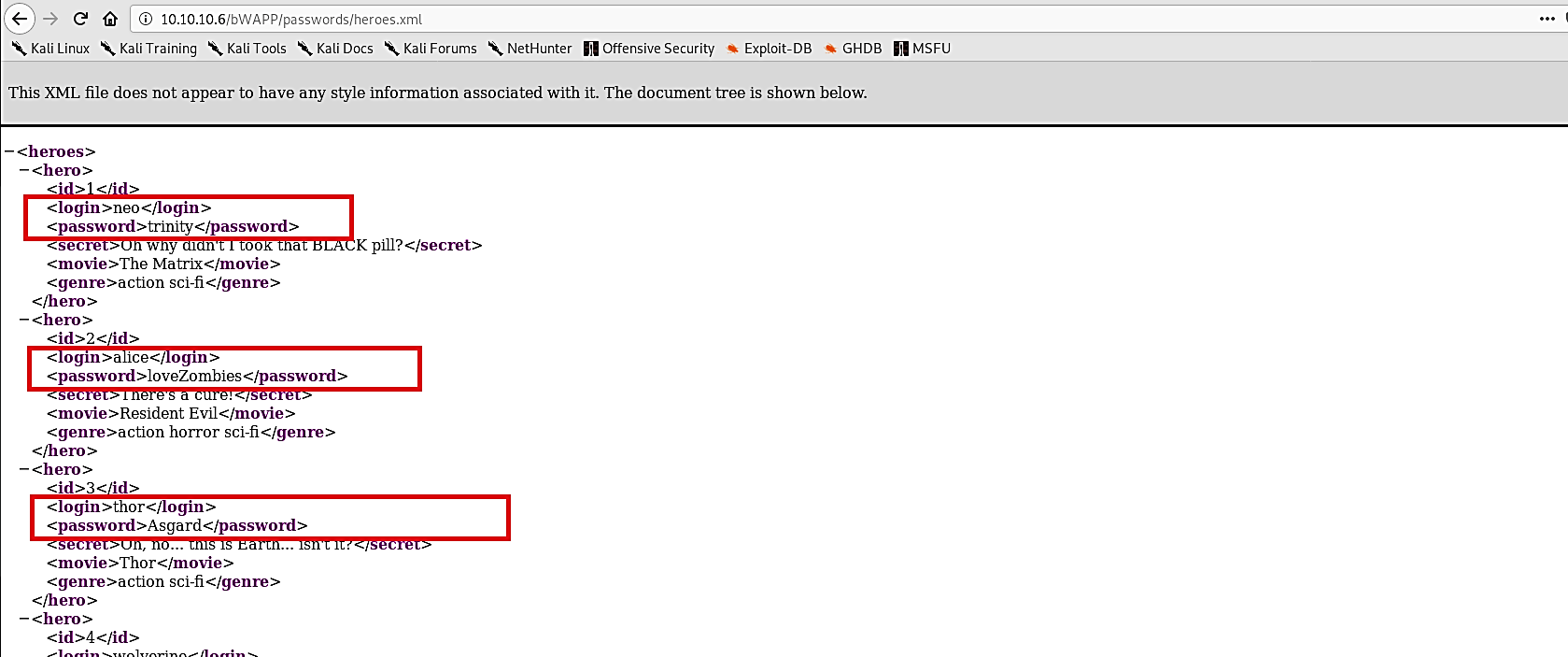
To view all available login information, use the “10.10.10.6/bWAPP/passwords/” URL and click on the “heroes.xml” file.

This page will list usernames and passwords in XML format.
The “robots.txt” record isn’t a security danger by itself, and its right use can represent an excellent practice for non-security reasons. You should not expect that all web robots will honor the file’s guidelines. Instead, accept that aggressors will give close consideration to any areas distinguished in that file. Try not to depend on “robots.txt” to provide any security over unapproved access.